

Logic Programming with Perl and Prolog
Computing languages can be addictive; developers sometimes blame themselves for perceived inadequacies, making apologies for them. That is the case, at least, when one defends his or her language of choice against the criticism of another language’s devotee. Regardless, many programmers prefer one language, and typically ground that preference in a respect for that language’s strengths.
Perl has many strengths, but two most often cited are its adaptability and propensity to work as a “glue” between applications and/or data. However, Perl isn’t the only advantageous language: programmers have used C or even assembly to gain speed for years, and intelligent use of SQL allows the keen coder to offload difficult data manipulations onto a database, for example. Prolog is an often overlooked gem that, when combined with the flexibility of Perl, affords the coder powerful ways to address logical relationships and rules. In this article, I hope to provide a glimpse of the benefits that embedded Prolog offers to Perl programmers. Moreover, I hope that my example implementation demonstrates the ease with which one can address complex logical relationships.
A Bit About Prolog
For the sake of demonstration, I would like to frame a simple problem and solution that illustrate the individual strengths of Perl and Prolog, respectively. However, while I anticipate that the average reader will be familiar with the former, he or she may not be as familiar with the latter. Prolog is a logic programming language often used in AI work, based upon predicate calculus and first developed in 1972. There are several excellent, free versions of Prolog available today, including GNU Prolog and the popular SWI Prolog. For the Prolog initiate, I recommend checking out some of the free Prolog tutorials, either those linked from Wikipedia or from OOPWeb.
Prolog and Perl aren’t exactly strangers, however. There are several excellent Perl modules available to allow the coder to access the power of Prolog quite easily, including the SWI module developed by Robert Barta, the Interpreter module by Lee Goddard, the Yaswi modules developed by Salvador Fandino Garcia, and the AI::Prolog module written by Curtis “Ovid” Poe. Poe has also recently provided a rather nice introduction to Prolog-in-Perl in an online-accessible format.
The Problem
There are many advantages to using Prolog within Perl. In the general sense, each language has its own advantages, and can thus complement the other. Suppose that I am building a testing harness or a logic-based query engine for a web application, where neither language easily provides all of the features I need. In cases such as these, I could use Prolog to provide the logic “muscle,” and Perl to “glue” things together with its flexibility and varied, readily available modules on CPAN.
In my simple demonstration, I am going to posit the requirement that I take genealogical information built by another application and test relationships based upon a set of rules. In this case, the rules are defined in a Prolog file (an interesting intersection here is that both Perl and Prolog typically use the suffix .pl), while the genealogical information is contained in a Dot file readable by Graphviz. As such, I am going to make certain assumptions about the format of the data. Next, I am going to assume that I will have a query (web-based, or from yet another application) that will allow users to identify relationships (such as brothers, cousins, etc.).
Here are my Prolog rules:
is_father(Person) :- is_parent(Person, _),
is_male(Person).
is_father(Person, Child) :- is_parent(Person, Child),
is_male(Person).
is_mother(Person) :- is_parent(Person, _),
is_female(Person).
is_mother(Person, Child) :- is_parent(Person, Child),
is_female(Person).
ancestor(Ancestor, Person) :- is_parent(Ancestor, Person).
ancestor(Ancestor, Person) :- is_parent(Ancestor, Child),
ancestor(Child, Person).
is_sibling(Person, Sibling) :- is_parent(X, Person),
is_parent(X, Sibling).
is_cousin(Person, Cousin) :- is_parent(X, Person),
is_parent(Y, Cousin),
is_sibling(X, Y).
One advantage to separating my logic is that I can troubleshoot it before I even write the Perl code, loading the rules into a Prolog interpreter or IDE such as XGP (for Macintosh users) and testing them. However, AI::Prolog conveniently provides its own solution: by typing aiprolog at the command line, I can access a Prolog shell, load in my file, and run some tests.
At this point, however, I am mostly interested in accessing these rules from Perl. While there are several options for accessing Prolog from within Perl, the AI::Prolog module is perhaps the easiest with which to start. Moreover, it is quite simple to use, the rules used to build the Prolog database being fed in when creating the AI::Prolog object. The ability to hand the object constructor a filehandle is not currently supported, but would indeed be a nice improvement. While there are other ways to accomplish the task of reading in the data, such as calling the Prolog command consult, I will read in the Prolog file (ancestry.pl) and provide a string representation of the contents.
open( PROLOGFILE, 'ancestry.pl' ) or die "$! \n";
local $/;
my $prologRules = <PROLOGFILE>;
close( PROLOGFILE );
my $prologDB = AI::Prolog->new( $prologRules );
Now that I have loaded my Prolog database, I need to feed it some more information. I need to take my data, in Dot format, and translate it into something that my Prolog interpreter will understand. There are some modules out there that may be helpful, such as DFA::Simple, but since I can assume that my data will look a certain way–having written it from my other application–I will build my own simple parser. First, I am going to take a look at the data.
The visualization program created the diagram in Figure 1 from the code:
digraph family_tree {
{ jill [ color = pink ]
rob [ color = blue ] } -> { ann [ color = pink ]
joe [ color = blue ] } ;
{ sue [ color = pink ]
dan [ color = blue ] } -> { sara [ color = pink ]
mike [ color = blue ] } ;
{ nan [ color = pink ]
tom [ color = blue ] } -> sue ;
{ nan
jim [ color = blue ] } -> rob ;
{ kate [ color = pink ]
steve [ color = blue ] } -> dan ;
{ lucy [ color = pink ]
chris [ color = blue ] } -> jill ;
}
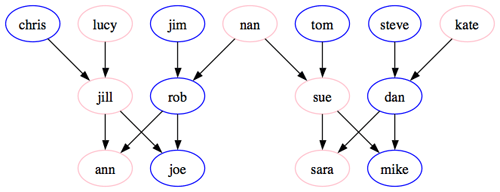 *Figure 1. A family tree from the sample data*
*Figure 1. A family tree from the sample data*
There are a few peculiarities worth mentioning here. First, it may seem that the all-lower-case names are a bit strange, but I am already preparing for the convention that data in Prolog is typically lower-case. Also, I inserted an extra space before the semicolons in an effort to make matching them easier. While both of these conventions are easy to code around, they seems to create extra questions when illustrating a point. Therefore, assume that the above Dot snippet illustrates the range of possible formats in the example. While the “real-world examples” may provide a richer set of possibilities, the fact that applications with defined behavior generated this data will limit the edge cases.
Returning to the data, it will be easiest to parse the Dot data using a simple state machine. Previously, I had defined some constants to represent states:
use constant { modInit => 0,
modTag => 1,
modValue => 2 };
Basically, I assume that anything on the left-hand side of the = is a parent and anything on the right is a child. Additionally, modifiers (in this case only color) begin with a left square-bracket and males have the blue modifier, whereas females are pink. I know that I have completed a parent-child relationship “block” when I hit the semicolon. Past these stipulations, if it isn’t a character I know that I can safely ignore, then it must be a noun.
sub parse_dotFile {
##----------------------------------------
## Examine data a word at a time
##----------------------------------------
my @dotData = split( /\s+/, shift() );
my ( $familyBlock, $personName, @prologQry ) = ();
my $personModPosition = modInit;
my $relationship = 'parent';
for ( my $idx = 3; $idx < @dotData; $idx++ ) {
chomp( $dotData[$idx] );
SWITCH: {
## ignore
if ( $dotData[ $idx ] =~ /[{}=\]]/ ) {
last SWITCH; }
## begin adding attributes
if ( $dotData[ $idx ] eq '[' ) {
$personModPosition = modTag;
last SWITCH; }
## switch from parents to children
if ( $dotData[ $idx ] eq '->' ) {
$relationship = 'child';
last SWITCH; }
## end of this block
if ( $dotData[ $idx ] =~ /\;/ ) {
##-----------------------------------------
## Generate is_parent rules for Prolog
##-----------------------------------------
foreach my $parentInBlock ( @{ $familyBlock->{ parent } } ) {
foreach my $childInBlock ( @{ $familyBlock->{ child } } ) {
push( @prologQry,
"is_parent(${parentInBlock}, ${childInBlock})" );
}
}
$familyBlock = ();
$relationship = 'parent';
last SWITCH; }
## I have a noun, need to set something
else {
## I have a modifier tag, next is the value
if ( $personModPosition == modTag ) {
$personModPosition = modValue;
last SWITCH;
} elsif ( $personModPosition == modValue ) {
##--------------------------------------
## Set modifier value and reset
## We currently assume it is color
##--------------------------------------
if ( $dotData[ $idx ] eq 'blue' ) {
push( @prologQry, "is_male(${personName})" );
} else {
push( @prologQry, "is_female(${personName})" );
}
$personModPosition = modInit;
$personName = ();
last SWITCH;
} else {
##--------------------------------------
## Grab the name and id as parent or child
##--------------------------------------
$personName = $dotData[ $idx ];
push( @{ $familyBlock->{ $relationship } }, $personName );
}
}
}
}
return( \@prologQry );
}
Rather than simply pushing my new rules into the Prolog interpreter directly, I return an array that contains the full ruleset. I am doing this so that I can easily dump it to a file for troubleshooting purposes. I can simply write the rules to a file, and consult this file in a Prolog shell.
With a subroutine to parse my Dot file into Prolog rules, I can now push those rules into the interpreter:
##-------------------------------------------
## Read in Dot file containing relations
## and feed it into the Prolog instance
##-------------------------------------------
open( DOTFILE, 'family_tree.dot' ) or die "$! \n";
my $parsedDigraph = parse_dotFile( <DOTFILE> );
close( DOTFILE );
foreach ( @$parsedDigraph ) {
$prologDB->do("assert($_).");
}
Now I can easily query my Prolog database using the query method in AI::Prolog:
##-------------------------------------------
## Run the query
##-------------------------------------------
$prologDB->query( "is_cousin(joe, sara)." );
while (my $results = $prologDB->results) { print "@$results\n"; }
What Next?
Even though this is a trivial example, I think that it provides an idea of the powerful ways in which Perl can be supplemented with Prolog. Just within the context of evaluating genealogical data (a mainstay of Prolog tutorials and examples), it seems that a Perl/Prolog application that uses genealogical data from open source genealogical software or websites would be a killer application. The possibilities seem endless: rules based upon Google maps, mining information from online auctions or news services, or even harvesting information for that new test harness are all tremendous opportunities for the marriage of Perl and Prolog.
Tags
Feedback
Something wrong with this article? Help us out by opening an issue or pull request on GitHub
Site Map
License
This work is licensed under a Creative Commons Attribution-NonCommercial 3.0 Unported License.

Legal
Perl.com and the authors make no representations with respect to the accuracy or completeness of the contents of all work on this website and specifically disclaim all warranties, including without limitation warranties of fitness for a particular purpose. The information published on this website may not be suitable for every situation. All work on this website is provided with the understanding that Perl.com and the authors are not engaged in rendering professional services. Neither Perl.com nor the authors shall be liable for damages arising herefrom.