

A slow boat to data
Data::Dump::Tree aims to render your data structures in a more legible way. It’s usefulness grows with the amount of data to display.
It’s not the best for dumping three variables that you will never see again but it’s good at rendering complex data, rendering what you generate often, and rendering what will be read by other people.
Installation
You can install it with zef, which comes with Rakudo Star:
zef install Data::Dump::Tree
The Data::Dump::Tree repo has two branches: release which is the branch zef installs and master which is the main development branch. I chose to develop on the latest Rakudo because bugs are fixed there. I may change the release branch to work only with Rakudo releases in the near future. There are tests to check the fitness of the module.
It’s not often that an article starts with a call for help but I have noticed that they tend to be forgotten when put at the end. There are a few things that can get better; please help if you can! The help list is at the end of the article.
The Legibility Principles
My idea is to make data rendering so simple and attractive that it removes the need to manually extract the relevant information from the data. Instead via filters present data that is simple enough for the end user and still detailed enough for a developer.
Data::Dump::Tree displays the data vertically which reduces the text/surface ratio. I try to apply a few principles:
- Limit the text to area ratio; a screen packed with text is useless; maximal concentration of text has low legibility
- Contrast the rendering with color, symbols, font size, and spacing
- Simplification - show less data as fewer details increases the render legibility
- Organization - transformed or tabulated data can make data easier to interpret
- Relationships - relationships contextualize the data, I achieve that by numbering and coloring the render
- Interactive - you can collapse or expand data to manage the complexity of the render
dd vs ddt
There is no doubt whatsoever that the dd builtin to Rakudo is many times faster than my ddt but here are some examples that, in my opinion, are much more readable when rendered by ddt.
[1..100] examples
use Data::Dump::Tree ;
dd [1..100] ;
ddt [1..100] ;
dd’s output is an example of compactness—clear and to the point.

ddt lists data vertically so we get a long rendering that looks like this (I truncated the output to the first 24 lines):

This is a clear advantage of dd’s horizontal layout but let’s see what ddt can do and when it may be more legible than dd.
ddt has a :flat mode that changes the rendering orientation. It’s true that it can take a long time to render large data structures but I find those large data structure are unreadable in a compact rendering so all I’m really doing is exchanging rendering time for comprehension time.
Let’s render the array of 100 elements in columns with 5 elements each:
use Data::Dump::Tree ;
ddt [1..100], :flat({1, 5, 10}) ;
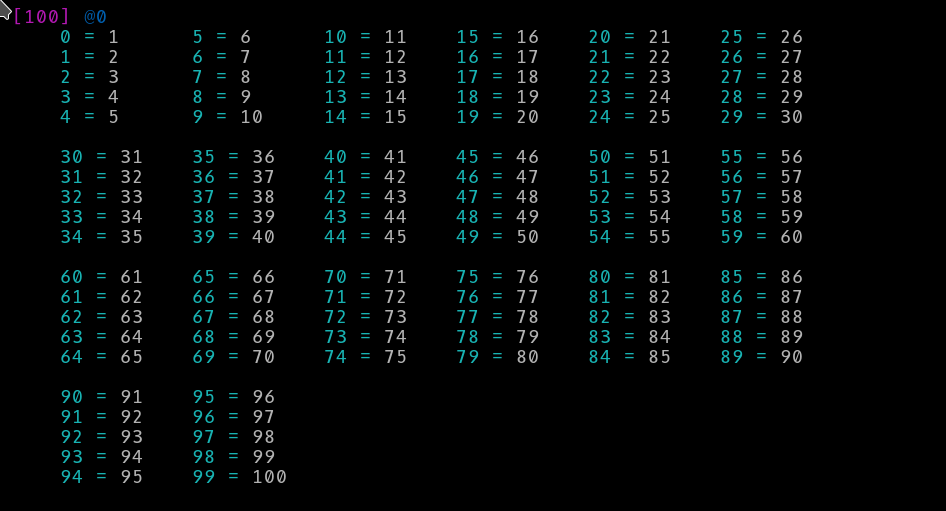
That’s a bit better and shorter but all those indexes add a bit of noise. Or does it add noise? The data I am rendering is so simple that I don’t need any indexing. What if the data weren’t sorted? What if I wanted to look at the value at the 50th index?
Here is an example with randomized data. I also used columns of 10 rows rather than 5. Still finding dd’s output better?:
use Data::Dump::Tree ;
dd True, [(1..100).pick: 100] ;
ddt True, [(1..100).pick: 100], :flat({1, 10, 10}) ;
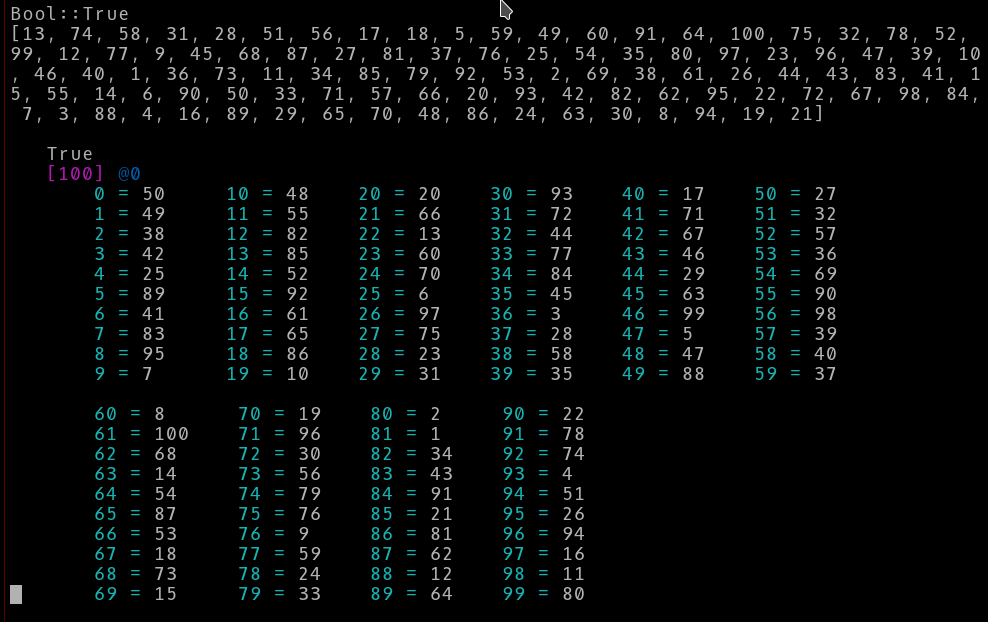
Still not convinced? What about 300 random integers? Can you navigate that?
dd True, [(1..300).pick: 300] ;
Let’s make it a bit more complicated. I want to see the values that are between 50 and 59. Imagine I am going to present this data over and over and spending a few minutes changing how Arrays are displayed is worth it to me:
use Data::Dump::Tree ;
use Data::Dump::Tree::DescribeBaseObjects ; # for DVO
use Terminal::ANSIColor ;
role skinny
{
multi method get_elements (Array $a)
{
$a.list.map:
{
'',
'',
50 <= $_ < 60
?? DVO(color('bold red') ~ $_.fmt("%4d") ~ color('reset'))
!! DVO($_.fmt("%4d"))
}
}
}
ddt True, [(1..100).pick: 100], :flat({1, 10}), :does[skinny] ;
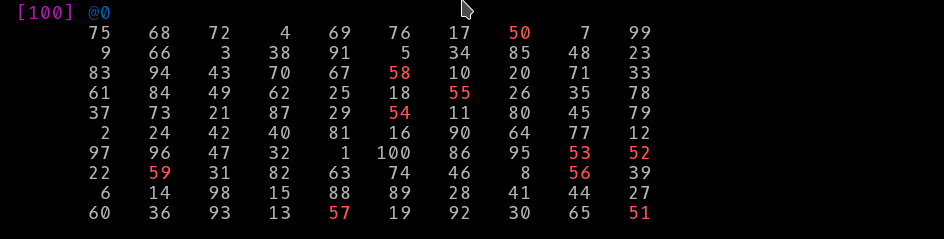
I could have displayed a table or a text mode graph. That’s even better when my data has a non-builtin type; I write a handler and give it to ddt and all instances will be rendered as I wish. I can write a filter and take over how other types are displayed, including the built-ins. Data::Dumper::Tree is all about giving me control of how data is rendered with a few sensible defaults.
The project repo has more examples.
Builtin versus user types
Although ddt handles quite a few builtin types, there are still some types I have not taken the time to look at. Those types may render wrongly or not at all. If you catch one of those, please open an issue in GitHub. And if you add a handler for the type, please submit a pull request! You can look at DescribeBaseObjects.pm to see what’s already handled.
User defined types are handled in a generic way. If they define ddt_* methods those will be called; otherwise the type attributes will be shown. The documentation has more information about this.
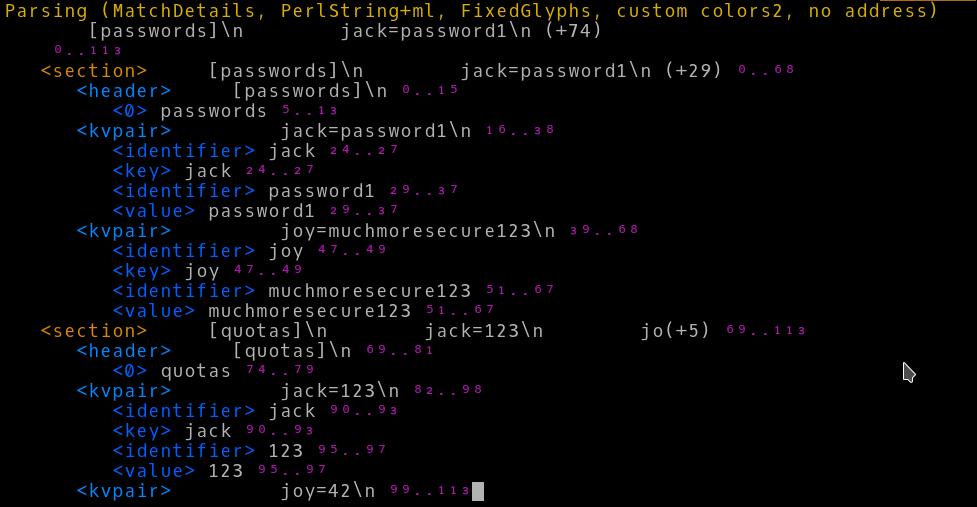
Match
In a review of Dumpers, brian noted that ddt output is not very interesting for Matches, and he was right. Not only is the default output not helpful but it even tries to hide all the details of the match. The reason for this is that there are details in a Match object that are usually of no use when rendering.
What if I want to see Match details in a data rendering? ddt has a role I can use that will make it more useful when working with Matches. There are examples of the Match role usage with and without extra filtering and coloring in examples/match.pl.
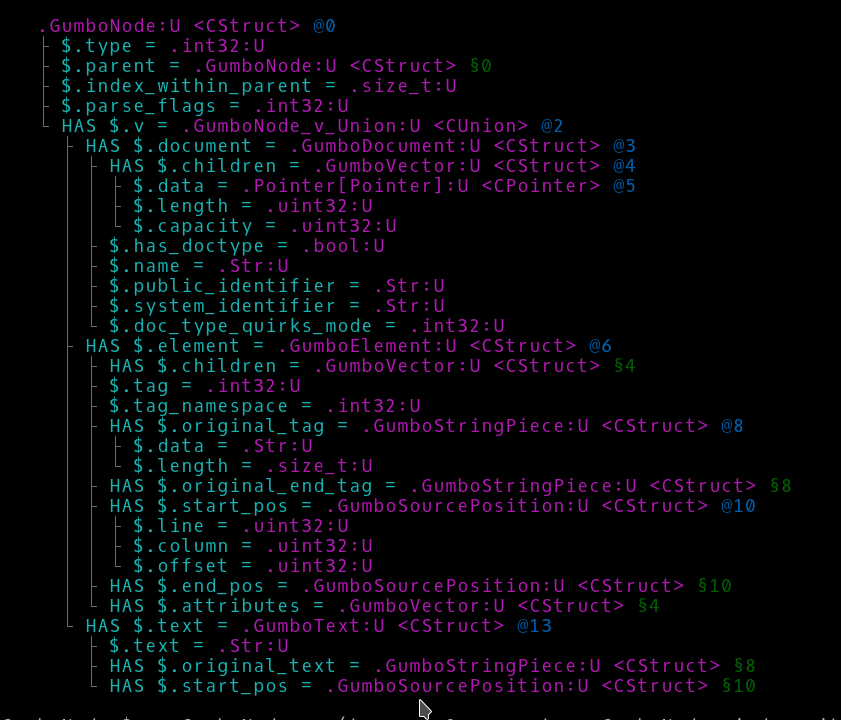
NativeCall Types
Look at examples/gumbo.pl. ddt can handle Perl 6’s NativeCall support. dd simply displays the type GumboNode. The ddt output breaks it down and annotates the C portions of the data structure:
Filtering
You have seen an example of handler in the [1..100] examples. Here is an example of filter applied to the parsing of a JSON data structure:
sub header_filter
($dumper, \r, $s, ($depth, $path, $glyph, @renderings),
(\k, \b, \v, \f, \final, \want_address))
{
# simplifying the rendering
# <pair> with a value that has no sub elements can be
# displayed in a more compact way
if k eq "<pair>"
{
my %caps = $s.caps ;
if %caps<value>.caps[0][0].key eq 'string'
{
v = ls(~%caps<string>, 40) ~ ' => ' ~ ls(~%caps<value>, 40) ;
final = DDT_FINAL ;
}
}
# Below need no details
if k eq "<object>" | "<pairlist>" | "<array>" | '<arraylist>'
{
v = '' ;
f = '' ;
}
}
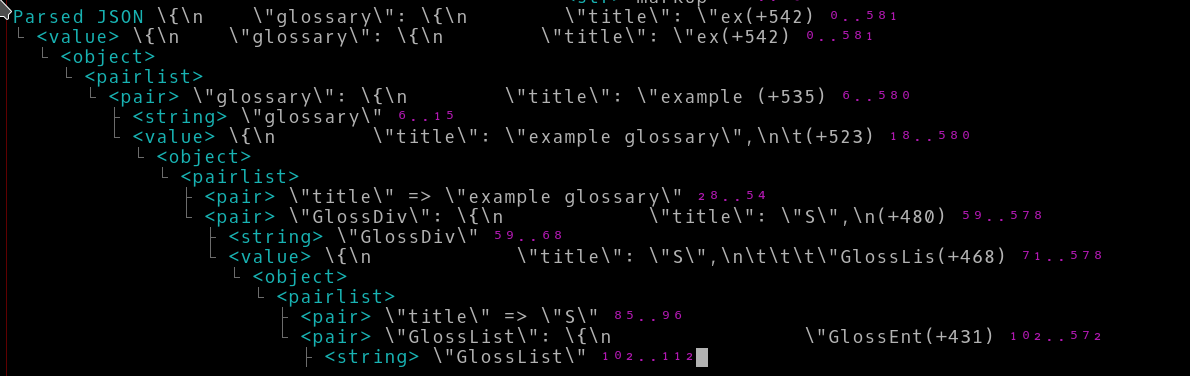
By applying the above filter, the amount of data displayed is reduced by a factor of almost three. The output without the filter:
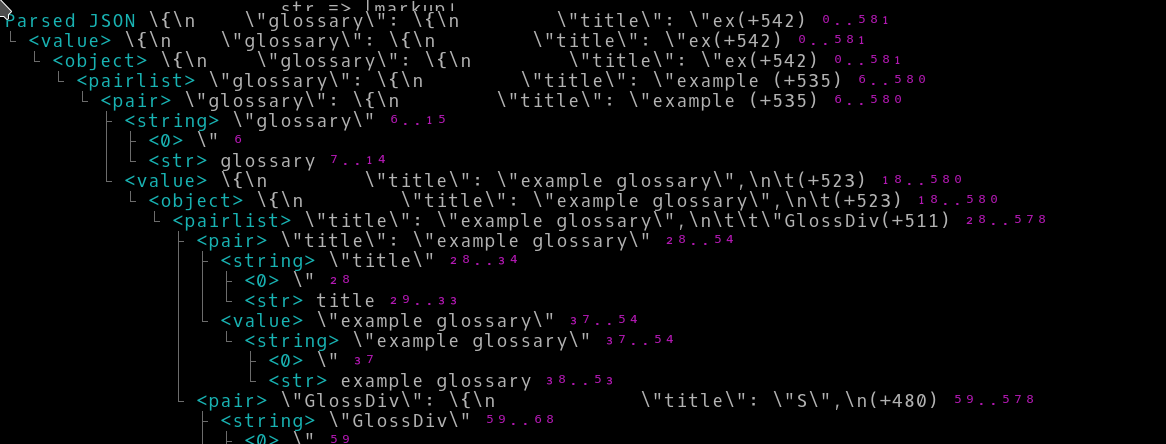
The output with the filter:
Folding And Sharing
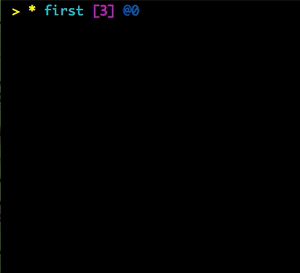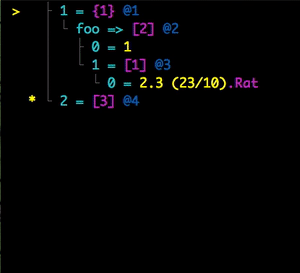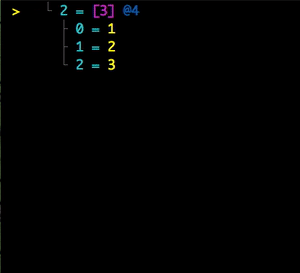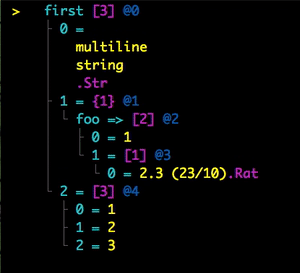
I can display a rendered data structure in a curses interface by using the :curses adjective:
ddt $data_structure, :curses;
I can also send the rendering of a data structure to another process. This makes it easier to debug without cluttering the display for example.
ddt $data_structure, :remote;
Less commonly used options
:nladds a blank line at the end of the rendering.:indentindents the whole rendering:!display_info,:!display_address,:!display_typethese remove the type/address from the rendering, for simple data this can improve the legibility
Getting Help
I can be found on the #perl6 IRC channel and will receive mail if an issue is opened on GitHub. I’m happy to help with general explanations and writing handlers/filters for new types or your types, especially if I can add it to the examples section.
Lending a hand
There are several areas that could use some help. Perhaps you can work on one of these:
- There is a DHTML renderer which could use some love. There is no visual cue for folded containers. The search functionality needs polishing too. I am no web person so the code represents my best effort so far
ddtsupport for builtin types can be expanded. That is best done by testing in your scripts and reporting when a type is not supportedddtis sluggish; it does a lot of things but it could do them faster. I tried profiling it but did not get very far. If you are proficient in Perl 6 and would like to have a look at the code, I will be happy to assist- You could write a data display application that would accept data structures via a socket and present them to the user. It should display multiple renderings and let the user chose which rendering to display. A bit like a log viewer but for data renderings
- Become a co-maintainer and help maintain the module!
Other articles/links
- Perl 6 Data::Dump::Tree version 1.5
- Take a walk on the C side, ddt, du du, du du …
- Show me the data!
Data::Dump::Treeis the continuation of my Perl 5 module Data::TreeDumper
Tags
Feedback
Something wrong with this article? Help us out by opening an issue or pull request on GitHub

