

Making Dictionaries with Perl
When you woke up this morning, the last thing you are likely to have thought is “If only I had a dictionary!” But there are thousands of languages on Earth that many people want to learn, but they can’t, because there are little or no materials to start with: no Pocket Mohawk-English Dictionary, no Cherokee Poetry Reader, no Everyday Otomi: Second Year. Only in the past few years have people realized that these languages are not just curiosities, but are basic indispensable, untranslatable parts of local cultures – and they’re disappearing in droves.
As I was learning Perl, the long arm of coincidence put me in contact with a good number of linguists who work on producing materials to help the study of these endangered languages. These folks work on producing textbooks and other “language materials,” which is mostly straightforward, since the 1980s gave us “desktop publishing.” But there was one real trouble spot: dictionaries. Writing a dictionary of any real size using just a word processor is maddening, like writing a novel on Post-Its. So they started using database programs, but had no way to turn this into anything you could print and call a dictionary. They had no way to take this:
Headword: dagiisláng
Citation: HSD
Part of speech: verb
English: wave a piece of cloth
Example: Dáayaangwaay hal dagiislánggan. | He was waving a flag.
And turn it into this:
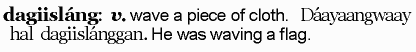
“Well,” I said and have been saying ever since, “This is no big deal, for you see, I am a programmer! Just export your database as CSV or something, email it to me, and I’ll write a program that reads that and writes out a word-processor file with everything formatted all nice just like you want.”
“A mere person, you, can program something that writes a word-processing document? But how can this be?! Surely this would require a year’s work, a million lines of C++, and a bajillion dollars!”
“Yes. But instead I’ll just use Perl, where I can do it in a few dozen lines of code, taking me just a few minutes.” Because, you see, a conventionally formatted dictionary is just a glorified version of what people with business degrees would call a “database report”, and people who work in cubicles generate such things all the time. And now I’ll show you how it’s done.
Reading the Input
Of course you’ll need Perl, and that’s not hard to come by. Then, at most, you just need a module for the input format and a module for the output format. And you don’t even need that if the input and/or output formats are simple enough. In this case, the input format I’m often given is simple enough. It’s called Shoebox Standard Format, and it looks like this:
\hw dagiisláng
\cit hsd
\pos verb
\engl wave a piece of cloth
\ex Dáayaangwaay hal dagiislánggan. | He was waving a flag.
\hw anáa
\cit hsd; led-285
\pos adverb
\engl inside a house; at home
\hw súut hlgitl'áa
\cit hsd; led-149; led-411
\engl speak harshly to someone; insult
\ex 'Láa hal súut hlgitl'gán. | She said harsh words to her.
\hw tlak'aláang
\cit led-398
\pos noun
\engl the shelter of a tree
Namely, \fieldname fieldvalue, each record (“entry”) starting with a \hw field, and the records and fields being in no particular order. (And the data, incidentally, is vocabulary from Haida, an endangered language spoken in the Southeast Alaskan islands, where I live.)
Now, one could parse this with a regexp and a bit of while(<IN>) {...}, but there’s already a module for this that will read in a whole file as a big data list-of-lists data structure. After just a glance at the module’s documentation, we can write this simple program to read in the lexicon as an object, and dump it to make sure that it’s getting well filled in:
use Text::Shoebox::Lexicon;
my $lex = Text::Shoebox::Lexicon->read_file( "haida.sf" );
$lex->dump;
And that prints this:
Lexicon Text::Shoebox::Lexicon=HASH(0x15550f0) contains 4 entries:
Entry Text::Shoebox::Entry=ARRAY(0x1559104) contains:
hw = "dagiisláng"
cit = "hsd"
pos = "verb"
engl = "wave a piece of cloth"
ex = "Dáayaangwaay hal dagiislánggan. | He was waving a flag."
Entry Text::Shoebox::Entry=ARRAY(0x1559194) contains:
hw = "anáa"
cit = "hsd; led-285"
pos = "adverb"
engl = "inside a house; at home"
Entry Text::Shoebox::Entry=ARRAY(0x155920c) contains:
hw = "súut hlgitl'áa"
cit = "hsd; led-149; led-411"
engl = "speak harshly to someone; insult"
ex = "'Láa hal súut hlgitl'gán. | She said harsh words to her."
Entry Text::Shoebox::Entry=ARRAY(0x1559284) contains:
hw = "tlak'aláang"
cit = "led-398"
pos = "noun"
engl = "the shelter of a tree"
A further glance shows that $lexicon->entries returns a list of the entry objects, and that $entry->as_list returns the entry’s contents as a list (key1, value1, key2, value2) – exactly the kind of list that is ripe for dumping into a Perl hash. So:
foreach my $entry ($lex->entries) {
my %e = $entry->as_list;
}
And that works perfectly, assuming we never have an entry like this:
\hw súut hlgitl'áa
\cit hsd; led-149; led-411
\engl speak harshly to someone
\engl insult
\ex 'Láa hal súut hlgitl'gán. | She said harsh words to her.
In that case, because there’s two “engl” fields, $entry->as_list would return this:
(
'hw' => "súut hlgitl'áa",
'cit' => "hsd; led-149; led-411",
'engl' => "speak harshly to someone",
'engl' => "insult",
'ex' => "'Láa hal súut hlgitl'gán. | She said harsh words to her.",
)
And once we dump that into the hash %e, we would end up with just this:
(
'hw' => "súut hlgitl'áa",
'cit' => "hsd; led-149; led-411",
'engl' => "insult",
'ex' => "'Láa hal súut hlgitl'gán. | She said harsh words to her.",
)
…since, of course, hash keys have to be unique in Perl hashes. If you needed to deal with a lexicon that had such entries, there are various methods in the Text::Shoebox::Entry class, but for a simple lexicon where each field comes up just once per entry, you can just use a hash – and you can even check that that’s the case by calling with $entry->assert_keys_unique;, which normally does nothing – unless it sees duplicate field names in that given entry, in which case it will abort the program and print a helpful error message about the offending entry.
But for our data, with its unique keys, a hash works just fine:
foreach my $entry ($lex->entries) {
my %e = $entry->as_list;
}
We would then do things with the contents of $e in that loop: either generating output right there, or putting it into Perl variables whose contents will later be output by other subroutines of ours.
Making the Output
Since we’ve got the basic input code squared away, now we get to think about how to output data. Once we know that, we’ll know better how to write the code to make the formats meet in the middle.
As output formats go, HTML is good for many purposes; practically all programmers can code in it pretty well, and just about everyone can hardcopy HTML with their browser or word processor. However, even after all these years, there are still some basic problems with HTML: as a typesetting language, there’s still no reliable support for control of page-layout options like headers and page-numbering, page breaks, newspaper columns, and the like. More importantly, WYSIWYG HTML editors all seem to be harmless at best or disastrous at worst. In my experience, that has ruled out HTML as an output format for the many lexicons where the output file still needs various kinds of manual touching-up in a word processor.
Because of these problems with HTML, I have generally chosen RTF as my output format. RTF is technically a Microsoft format, but somehow, somehow, it avoided most of the lunacy that that usually entails. Moreover, just about every word processor supports it. And Microsoft Word both prints and edits RTF pretty much flawlessly. (After all, it had to be good at something.) And finally, there’s good Perl support for generating RTF, via the CPAN modules RTF::Writer and RTF::Document, so you can almost completely insulate yourself from dealing directly with the language. I’ll use RTF::Writer, simply because I’m more familiar with it. (This may be due to the fact that it was written by the author of the delightful O’Reilly book RTF Pocket Guide, a handsome and charming man whose modesty forbids him from revealing that he is me.)
With a bit of skimming the RTF::Writer documentation, we can see that to send output to an RTF file, you create a sort of file handle for it, and then send data to it via its print or paragraph methods, like so:
use RTF::Writer;
my $rtf = RTF::Writer->new_to_file( "sample.rtf" );
$rtf->prolog(); # sets up sane defaults
$rtf->paragraph( "Hello world!" );
$rtf->close;
That writes an RTF document consisting of just a sane header and then basically the text, “Hello world!”:
{\rtf1\ansi\deff0{\fonttbl
{\f0 \froman Times New Roman;}}
{\colortbl;\red255\green0\blue0;\red0\green0\blue255;}
{\pard
Hello world!
\par}
}
The RTF::Writer documentation comes with a list of some basic escape codes that are basically all we need to format our lexicon. The notables are:
\b for bold
\i for italic
\f2 switch to font #2 (i.e., the second font we declare for this document)
\fs40 switch text size to 20-point (40 = how many half-points)
RTF::Writer’s interface is designed so that normal text passed to it will get escaped before being written to the RTF output file, and clearly you don’t want that to happen to these codes – you want the \b to be written as is, not escaped so that it’d show a literal backslash and a literal b in the document. To signal this to the RTF::Writer interface, you pass references to these strings, like so:
$rtf->paragraph( \'\i', "Hello world!" );
You can also limit the effect of a code by wrapping it in an arrayref, i.e., with [code, text], like so:
$rtf->paragraph(
"And ",
[ \'\i', "Hello world!" ],
" is what I say."
);
That’ll produce a document saying: And Hello world! is what I say.
That’s just about all the RTF we’d need to know to produce some simple lexicon output. We can exercise this with some literal text:
use RTF::Writer;
my $rtf = RTF::Writer->new_to_file( "lex.rtf" );
$rtf->prolog(); # sets up sane defaults
$rtf->paragraph(
[ \'\b', "tlak'aláang: " ],
[ \'\b\i', "n." ],
" the shelter of a tree"
);
$rtf->paragraph(
[ \'\b', "anáa: " ],
[ \'\b\i', "adv." ],
" inside a house; at home"
);
$rtf->close;
And that gets us something very close to the kind of formatting you’d find in a typical fancy dictionary:
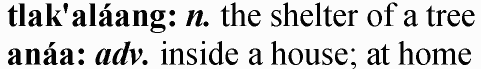
Of course, we’d like to tweak spacing and fonts a bit, but that can be left for later as just minor additions to the code. Knowing just as much as we do now, we can see the output code taking shape. It would be something like:
foreach my $entry (...) {
...
$rtf->paragraph(
[ \'\b', $headword, ": " ],
[ \'\b\i', $part_of_speech ],
" ", $english,
...and something to drop the example sentences, if any...
);
}
In fact, we can already cobble this together with our earlier input-reading code, to make a clunky but working prototype:
use strict;
use Text::Shoebox::Lexicon;
my $lex = Text::Shoebox::Lexicon->read_file( "haida.sf" );
use RTF::Writer;
my $rtf = RTF::Writer->new_to_file( "lex.rtf" );
$rtf->prolog(); # sets up sane defaults
foreach my $entry ($lex->entries) {
my %e = $entry->as_list;
$rtf->paragraph(
[ \'\b', $e{'hw'} || "?hw?", ": " ],
[ \'\b\i', $e{'pos'} || "?pos?" ],
" ", $e{'engl'} || "?english?"
);
}
$rtf->close;
And that produces this:
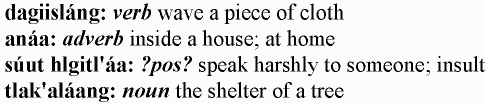
Now, sure, the entries aren’t in alphabetical order, we see “noun” instead of “n.”, and the example sentences aren’t in there yet. But consider that with not even twenty lines of Perl, we’ve got a working dictionary renderer. It’s downhill from here.
Sorting and Duplicate Headwords
So how do we take entries in whatever order, and put them into alphabetical order? A first hack is something like this:
my %headword2entry;
foreach my $entry ($lex->entries) {
my %e = $entry->as_list;
$headword2entry{ $e{'hw'} } = \%e;
}
foreach my $headword (sort keys %headword2entry) {
my %e = %{ $headword2entry{$headword} };
...and print it here...
}
And that indeed works fine. But suppose one of the linguists comes by and adds these three entries into our little database:
\hw gíi
\pos auxiliary verb
\engl already; always; often
\hw gu
\pos postposition
\engl there
\hw gíi
\pos verb
\engl swim away [of fish]
When we run our program, there’s trouble with the output:

First off, the second “gíi” (the verb for fish swimming away) was stored as $headword2entry{'gíi'} and that overwrote the first “gíi” entry (the one that means already, always, or often). And secondly, “gíi” got sorted after “gu”!
The first problem can be solved by changing from the current data structure, which is like this:
$headword2entry{ 'gíi' } = ...one_entry...;
over to a new data structure, which is like this:
$headword2entries{ 'gíi' } =
[ ...one_entry... , ...another_entry..., ...maybe_even_another... ];
…even though in most cases that list will hold just one entry.
That’s simple to graft into our program, even if the syntax for dereferencing gets a bit thick:
my %headword2entries;
foreach my $entry ($lex->entries) {
my %e = $entry->as_list;
push @{ $headword2entries{ $e{'hw'} } }, \%e;
}
foreach my $headword (sort keys %headword2entries) {
foreach my $entry ( @{ $headword2entries{$headword} } ) {
...code to print the entry...
}
}
And that works just right: both “gíi” entries show up.
Now how to get sort keys %headword2entries to sort “gíi” before “gu”? The default sort() that Perl uses just sorts ASCIIbetically, where “í” comes not just after “u”, but actually after all the unaccented letters. We can get Perl to use a smarter sort() if we add a “use locale;” line and see about changing our current locale to French or German or something that’d know that “í” sorts before “u”. This approach works in some cases, but suppose that you’re dealing with a language that uses “dh” as a combined letter that comes after “d”. You’d be out of luck, since there aren’t any existing locales that (as far as I know) that have “dh” as a letter after “d”, and since under most operating systems you can’t define you own locales.
But CPAN, once again, comes to the rescue. The CPAN module Sort::ArbBiLex lets you state a sort order and get back a function that sorts according to that order. We can just pull this example from the docs:
use Sort::ArbBiLex (
'custom_sort' => # that's the function name to define
"
a A à À á Á â Â ã Ã ä Ä å Å æ Æ
b B
c C ç Ç
d D ð Ð
e E è È é É ê Ê ë Ë
f F
g G
h H
i I ì Ì í Í î Î ï Ï
j J
k K
l L
m M
n N ñ Ñ
o O ò Ò ó Ó ô Ô õ Õ ö Ö ø Ø
p P
q Q
r R
s S ß
t T þ Þ
u U ù Ù ú Ú û Û ü Ü
v V
w W
x X
y Y ý Ý ÿ
z Z
"
);
And if we need that “dh” to be a new letter between “d” and “e”, it’s a simple matter of adding a line to the above code:
...
d D ð Ð
dh Dh
e E è È é É ê Ê ë Ë
...
And if the above sort order isn’t right, we can fix this by just moving things around. For example, a few Haida words use an x-circumflex character for an odd pharyngeal sound, and since that character isn’t in Latin-1, the folks working on Haida use a special font that replaces the Latin-1 þ character with the x-circumflex. To have that sort as a letter after x, we’d rearrange the end of the above sort-order to read like this:
...
t T
u U ù Ù ú Ú û Û ü Ü
v V
w W
x X
þ Þ
y Y ý Ý ÿ
z Z
Once we get the big use Sort::ArbBiLex (...); statement set up just the way we like it, we can just replace the “sort” in our “sort keys” with “custom_sort”, like so:
foreach my $headword (custom_sort keys %headword2entries) {
foreach my $entry ( @{ $headword2entries{$headword} } ) {
...code to print the entry...
}
}
With that in place, our entries sort just right:

Reverse Indexing
The last thing anyone wants to do when they’ve finished working on a dictionary, is to turn right around and write another one – but that’s exactly the problem that comes up in lexicography: you’ve been compiling a Haida-to-English dictionary, and then someone says “Gee, it’d be really handy to have an English-to-Haida one, too!”
In the bad old days before people used databases for their lexicons, this process of “reversing the dictionary” was manual. Now that we have databases, we just need a way to see the entry that expresses “gu” = “there” in our main lexicon, and then make an entry in a reverse lexicon that expresses “there” = “gu”.
The reverse lexicon could be just %english2native with entries like:
$english2native{'there'} = "gu";
But there could be several words that mean “there” – like “gyaasdáan” – so we’d have to use an array here, just as we did in %headword2entries, like this:
$english2native{'there'} = [ "gu", "gyaasdáan" ];
We can implement this by changing our initial lexicon-scanning routine to add a line to push to @{$english2native{each_english_bit}}, like so:
foreach my $entry ($lex->entries) {
my %e = $entry->as_list;
push @{ $headword2entries{ $e{'hw'} } }, \%e;
foreach my $engl ( reversables( $e{'engl'} ) ) {
push @{ $english2native{ $engl } }, $e{'hw'}
}
}
And later on, we can spit out the contents of %english2native after the main dictionary:
$rtf->paragraph( "\n\nEnglish to Haida Index\n" );
foreach my $engl ( custom_sort keys %english2native) {
my $n = join "; ", custom_sort @{ $english2native{ $engl } };
$rtf->paragraph( "$engl: $n" );
}
All we need now is a routine, reversables(), that can take the string “already; always; often” (from the gíi entry) and turn it into the list (“already,” “always,” “often”), and to take the string “the shelter of a tree” and turn it into the one-item list ("shelter of a tree"). (If we left the “the” on there, we’d have a huge bunch of entries under “the”!)
This function is a decent first hack:
sub reversables {
my $in = shift || return();
my @english;
foreach my $term ( split /\s*;\s*/, $in ) {
$term =~ s/^(a|an|the|to)\s+//i;
# Take the "to" off of "to swim away [of fish]",
# and the "the" off of "the shelter of a tree"
push @english, $term;
}
return @english;
}
However, consider the entry anáa: “inside a house; at home” – our reversables() function will return this as the list ("inside a house", "at home"). That seems passable, but if I were looking for a word like this in the English end of the dictionary, I’d probably want it to be under “home” and “house” as well.
Now, there are four alternatives here for how to have finer control over the reversing:
Just don’t bother, and instead just do this all manually in the editing of the final draft. This is a bad approach because, in my experience, the people working on the lexicon get so used to the just-passable reversing algorithm that they end up thinking it’s no big deal, and so in the end its effects never get fixed.
Don’t do automatic reversing, but have a mandatory field in each entry that says what English headword(s) should point to this native entry. For example, if we call the field “ehw” (for “English headword”), then for “at home; inside a house” could say something like: “\ehw home, at; house, inside a”. However, having this be mandatory is a real drag for simple entries like “gu,” where you’d have to do:
\hw gu
\engl there
\ehw there
* Make an “ehw” field optional, and when it’s absent, use a smart reversing algorithm. So when we have an entry like “\hw gu \engl there”, of course the reversing algorithm would know to infer a “\ehw there.” And it would somehow be smart enough to know to index “wave a piece of cloth” under “wave” and “cloth” but not under “a,” “piece,” or “of.” The problem with very smart fallback algorithms like this is that people have to understand them completely, so that they can know whether the result is good enough or whether it should be overridden with a default “\ehw” field. But since nobody can remember all the hacks that get built into the smart algorithm, they either err on the side of doubt by always putting a “\ehw” field (thus making the whole algorithm pointless), or by never putting a “\ehw” field, or, worse some unpredictable and headachy mix of the two. So ironically, a smart fallback algorithm is often a bad idea. That leads us to the final alternative:
* Make an “ehw” field optional, and when it’s absent, use a dumb reversing algorithm. By “dumb,” I mean a maximum of two rules – if it’s any more complex than that, people will forget how it works and won’t know when they should key in an explicit “\ehw” field.
So while we could add more and more things to our reversables() algorithm, it seems wisest to refrain from doing this, to be content with our one s/^(a|an|the|to)\s+//i rule, and instead just add support for an “\ehw” field. We can do that simply by changing the call to reversables(), from this:
foreach my $engl ( reversables( $e{'engl'} ) ) {
push @{ $english2native{ $engl } }, $e{'hw'}
}
to this:
my @reversed = $e{'ehw'} ? split( m/\s*;\s*/, $e{'ehw'} )
: reversables( $e{'engl'} );
foreach my $engl ( @reversed ) {
push @{ $english2native{ $engl } }, $e{'hw'}
}
With that in place (and with a “\ehw home, at; house, inside a” line in the “anáa” entry just to get the ball rolling), our program runs and spits out an English index after the Haida dictionary:

Conditional Output and Example Sentences
There’s two optional parts of the entries that we haven’t used yet: the citation fields, like “\cit hsd; led-149; led-411”, and the example sentences field, like “\ex ‘Láa hal súut hlgitl’gán. | She said harsh words to her.”. The citation fields are typically only of importance to the editors, who might want to spot-check words against the places in the text where they were found. (And typically the editors are the only ones who would be fluent with the abbreviations, e.g., would know that “led-149” is short for “page 149 of the Leer-Edenso Dictionary of Haida”.)
Ideally our program should produce output for the editors with the citations, and output for normal users (without the citations). We can do this my having a $For_Editors variable that’s set early on in the program:
my $For_Editors = 0; # set to 1 to add citations
And then later on we have code that uses that variable:
foreach my $headword ( custom_sort keys %headword2entries) {
foreach my $entry ( @{ $headword2entries{$headword} } ) {
print_entry( $entry );
}
}
sub print_entry {
my %e = %{$_[0]};
$rtf->paragraph(
[ \'\b', $e{'hw'} || "?hw?", ": " ],
[ \'\b\i', $e{'pos'} || "?pos?" ],
" ", $e{'engl'} || "?english?", ".",
$For_Editors && $e{'cit'} ? " [$e{'cit'}]" : (),
);
}
Our new and punctuation-rich $For_Editors && $e{'cit'} line is just a concise way of saying “if this is for the editors and if there’s a citation in this entry, then print a space and a bracket before it, and a bracket after it – otherwise don’t add anything”.
Our example sentences ("\ex ‘Láa hal súut hlgitl’gán. | She said harsh words to her".) should probably end up in any normal dictionary, but of course we wouldn’t want to try adding the contents of $e{'ex'} with formatting codes around it if it weren’t actually present in this entry. We can use the same sort of $value ? "...$value..." : () idiom we used before – except that this time we need to first take out the “|” that separates the Haida part from the English translation. That’s simple, though:
my($ex, $ex_eng);
($ex, $ex_eng) = split m/\|/, $e{'ex'} if $e{'ex'};
$rtf->paragraph(
...
$ex_eng ? (" $ex = $ex_eng") : (),
);
With that code in place, our entries that have example sentences, show them, like this:
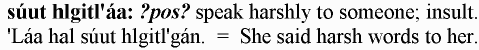
Fancier Formatting
Now that basically everything else about our program is working, how about we polish it off with some formatting codes to make it look just right. We’ve already got some simple bold and italic codes, so the next thing is certainly to use different fonts. We could use, say, Bookman for the main headword and Times for the rest of the entry – except for in the example sentence, we can use Bookman again for the Haida text, and Arial for the English translation.
However, a glance at the RTF Pocket Guide shows no RTF code that means “change to the font ‘Arial’” – just a code that means “change to font number N [i.e., the second font we declare for this document]”, This declaring is just a matter of adding a parameter 'fonts' = [ …font names…],> to that dull $rtf->prolog() method we called back when we created $rtf. As the RTF::Writer documentation notes, “You should be sure to declare all fonts that you switch to in your document (as with \’\f3’, to change the current font to what’s declared in entry 3 (counting from 0) in the font table).” So if we just change our prolog call to this…
$rtf->prolog( 'fonts' => [ "Times New Roman", "Bookman", "Arial" ] );
… Then we can use a \f0 to switch to Times New Roman (which is the default, incidentally, since it’s the first declared font), and \f1 to switch to Bookman, and \f2 to switch to Arial.
And suppose we want everything to be in 10-point, except for the Arial part, which we want in specifically 9-point Arial so it won’t steal attention from the rest of the text, as sans-serif fonts often do. That’s just a matter of a \fs20 and \fs18 code – “fs” for “font size”, plus the desired font size, in *half-*points. (Odd, I know.)
With these extra codes in place, our print_entry routine now looks like this:
sub print_entry {
my %e = %{$_[0]};
my($ex, $ex_eng);
($ex, $ex_eng) = split m/\|/, $e{'ex'} if $e{'ex'};
$rtf->paragraph( \'\fs20', # Start out in ten-point
[ \'\f1\b', $e{'hw'} || "?hw?", ": " ],
[ \'\b\i', $e{'pos'} || "?pos?" ],
" ", $e{'engl'} || "?english?", ".",
$For_Editors && $e{'cit'} ? " [$e{'cit'}]" : (),
$ex_eng ? (" ", \'\f1', $ex, \'\f2\fs18', $ex_eng) : (),
);
}
It’s dense, but then it does a lot of work! And that work comes out looking like this:

As to adding fancier formatting, this is usually best done by just flipping through the RTF Pocket Guide and looking for a mention of the effect you want. For example, in a lexicon we might be particularly interested in hanging indents (\fi-300), two-column pages (\col2), and page numbering ({\header \pard\ql\plain p.\chpgn \par}).
Now suppose that you’re trying to make the most of your xeroxing budget, trading off nice large readable point size against how many people get copies. One way to squeeze as much content into as small a space is to use abbreviations for the most repeated text in the dictionary – the part-of-speech tags. So we can turn “noun” into just “n.”, “verb” into “v.”, and so on. Each time, we save only a little space, but it adds up quick. And doing this (or at least trying it out to see how it looks) is straightforward. We need only change one line in print_entry(), from this
[ \'\b\i', $e{'pos'} || "?pos?" ],
To this:
[ \'\b\i', $Abbrev{$e{'pos'}||''} || $e{'pos'} || "?pos?" ],
And earlier we’ll have to define what should be in %Abbrev:
my %Abbrev = (
'auxiliary verb' => 'aux.',
qw(noun n. verb v. adverb adv.),
);
But that’s all it takes to change our output to look like this:

That continues to print “?pos?” when an entry is erroneously missing the part-of-speech field. And it doesn’t abbreviate the term “postposition”. (If we did so, it’d probably be “pp.”, which people would probably think was “participle” or something.) But the most common terms, “noun” and “verb”, got shrunk down, saving a few characters per entry, which could add up to a dozen pages in a large printout.
Other Formats
I’ve just been talking about producing conventionally formatted dictionaries, but the same database and the same kinds of Perl could be used to instead produce different output formats. Use a bit of fancy page layout and a double-sided printer (or copier) and the same data can be turned into readymade flashcards. Or if you have a subject field in entries (like “plant”, “color”, “body part”, “food”), it’s easy to re-sort entries by topic, and produce a “topical dictionary”, which language teachers find very useful in planning classroom exercises.
World Enough and Time
As A. N. Whitehead’s famous quote goes, “Civilization advances by extending the number of important operations which we can perform without thinking about them. Operations of thought are like cavalry charges in a battle - they are strictly limited in number, they require fresh horses, and must only be made at decisive moments.” I’ve found this to be personally and critically true in dealing with endangered languages: it takes man-years of time to produce a dictionary of any useful size, both on the part of linguists and of members of the community. And with most of North America’s native languages, the most fluent speakers are over 65, so there’s no great surplus of man-years.
Whitehead was more right than he knew: saving time and effort doesn’t just advance civilizations, it can help save them.
So when Perl helps us glue together a database program, a printer, and a word processor so that the typesetting phase of a dictionary takes not months, but minutes, this frees up the linguists and teachers and elders to spend scarce time and “decisive moments” working on preserving the language through study and teaching. We need every minute to work on revitalizing these languages that are the foundation of endangered cultures and civilizations – with all their stories, poems, songs, sayings, proverbs, figures of speech, jokes, liturgy, and heaps of specialized jargon from botany and agriculture and healing and just plain ways of relating to people and the world, very little of which would survive mere translation to English.
We’re in a hurry, and so we really appreciate Perl.
Finished Code for Sample Haida Dictionary
use strict;
use warnings;
my $For_Editors = 0; # set to 1 to add citations
use RTF::Writer;
use Text::Shoebox::Lexicon;
my $lex = Text::Shoebox::Lexicon->read_file( "haida.sf" );
my $rtf = RTF::Writer->new_to_file( "lex.rtf" );
$rtf->prolog( 'fonts' => [ "Times New Roman", "Bookman", "Arial" ] );
use Sort::ArbBiLex (
'custom_sort' =>
"
a A à À á Á â Â ã Ã ä Ä å Å æ Æ
b B
c C ç Ç
d D ð Ð
e E è È é É ê Ê ë Ë
f F
g G
h H
i I ì Ì í Í î Î ï Ï
j J
k K
l L
m M
n N ñ Ñ
o O ò Ò ó Ó ô Ô õ Õ ö Ö ø Ø
p P
q Q
r R
s S ß
t T þ Þ
u U ù Ù ú Ú û Û ü Ü
v V
w W
x X
y Y ý Ý ÿ
z Z
"
);
my %headword2entries;
my %english2native;
my %Abbrev = (
'auxiliary verb' => 'aux.',
qw(noun n. verb v. adverb adv.),
);
foreach my $entry ($lex->entries) {
my(%e) = $entry->as_list;
push @{ $headword2entries{ $e{'hw'} } }, \%e;
my @reversed = $e{'ehw'} ? split( m/\s*;\s*/, $e{'ehw'} )
: reversables( $e{'engl'} );
foreach my $engl ( @reversed ) {
push @{ $english2native{ $engl } }, $e{'hw'}
}
}
$rtf->paragraph( "Haida to English Dictionary\n\n" );
foreach my $headword ( custom_sort keys %headword2entries) {
foreach my $entry ( @{ $headword2entries{$headword} } ) {
print_entry( $entry );
}
}
$rtf->paragraph( "\n\nEnglish to Haida Index\n" );
foreach my $engl ( custom_sort keys %english2native) {
my $native = join "; ", custom_sort @{ $english2native{ $engl } };
$rtf->paragraph( "$engl: $native" );
}
$rtf->close;
exit;
sub reversables {
my $in = shift || return;
my @english;
foreach my $term ( grep $_, split /\s*;\s*/, $in ) {
$term =~ s/^(a|an|the|to)\s+//;
push @english, $term;
}
return @english;
}
sub print_entry {
my %e = %{$_[0]};
my($ex, $ex_eng);
($ex, $ex_eng) = split m/\|/, $e{'ex'} if $e{'ex'};
$rtf->paragraph( \'\fs20', # Start out in ten-point
[ \'\f1\b', $e{'hw'} || "?hw?", ": " ],
[ \'\b\i', $Abbrev{$e{'pos'}||''} || $e{'pos'} || "?pos?" ],
" ", $e{'engl'} || "?english?", ".",
$For_Editors && $e{'cit'} ? " [$e{'cit'}]" : (),
$ex_eng ? (" ", \'\f1', $ex, \'\f2\fs18', $ex_eng) : (),
);
}
Tags
Feedback
Something wrong with this article? Help us out by opening an issue or pull request on GitHub

