

Create RSS channels from HTML news sites
Even if you haven’t heard of the RSS acronym before, you’re likely to have used RSS in the past. Whether through the slashboxes at slashdot or our own news summary at use.perl.org, the premise remains the same - RSS, or “Remote Site Summary” is a method used for providing an overview of the latest news to appear on a site.
RSS is an XML-based format, where the the site’s information is described in a format that simplifies the news down to a few key elements. In the example we’re going to run through, we’ll concentrate particularly on the title and link tags. If you’re interested in specifics of RSS, you can read more about it and see the full specification at netscape.com; for the purposes of this tutorial, though, I’m going to concentrate on how we can manipulate RSS with Perl and leave RSS internals alone.
So, you have a news site requiring an RSS feed; or let’s say there’s a news site that you want to get into RSS format. O’Reilly’s own Meerkat web site creates RSS descriptions of the news on other sites, and presents the latest news from all around the web as a news ticket. We’re not going to use exactly the same method as Meerkat in this tutorial, but we’ll use similar techniques to provide us with an RSS feed of the BBC News web site.
So, what does our perl script need to do in order to turn the headlines on the site into an RSS channel? There are three main tasks that we’ll be handling:
- Downloading the page for our script to work with,
- Parsing the HTML on the page to give us meaningful summary information, and
- Encoding the summary information in RSS.
For anyone who’s used the huge CPAN network of modules before, it’s not going to be a huge surprise to hear that there are modules to help us accomplish each of our tasks here. We’re going to be using LWP::Simple to handle downloading our page, HTML::TokeParser to parse our downloaded HTML into some meaningful English, and XML::RSS to create an RSS channel from our headlines and links.
Let’s jump in to the code. After declaring our use of the modules we’re going to be using…
use strict;
use LWP::Simple;
use HTML::TokeParser;
use XML::RSS;
.. we’re ready to create each of the objects we’ll be using with each module. Note that while LWP::Simple uses a procedural interface, both HTML::TokeParser and XML::RSS have Object-Oriented interfaces. If you aren’t used to OO in Perl, Simon Cozens’ recent article on Object-Oriented Perl might be a great help.
# First - LWP::Simple. Download the page using get();.
my $content = get( "http://news.bbc.co.uk/" ) or die $!;
# Second - Create a TokeParser object, using our downloaded HTML.
my $stream = HTML::TokeParser->new( \$content ) or die $!;
# Finally - create the RSS object.
my $rss = XML::RSS->new( version => '0.9' );
Our next step in laying the foundations for our script is going to be to declare some variables and set the channel information on our RSS object. Every RSS channel carries some metadata; that’s to say, data which provides information about the data that it encodes. For instance, it usually carries at least the channel’s name, description, and an URL link. We’re going to set up the metadata by calling the channel method on our object, like this:
# Prep the RSS.
$rss->channel(
title => "news.bbc.co.uk",
link => "http://news.bbc.co.uk/",
description => "news.bbc.co.uk - World News from the BBC.");
# Declare variables.
my ($tag, headline, $url);
We now have all three of our modules primed and ready for use, and can move on to step two - obtaining plaintext information from our HTML page. This is where we need to apply our analytical skills to determine the layout of the web site we’re looking at, and to find out how to find the headlines we wish to extract. The BBC’s HTML layout is complex but predictable, and follows this routine:
- A
<div class="bodytext">tag is present. - An
<a>tag is opened, and then closed. - An
<a>tag is opened, containing the URL we wish to grab, linking to the full text of the news article. - The
<a>tag is closed, and a<b class="h1">or<b class="h2">tag is opened. - Our headline lies between this
<b>tag and a</b>tag.
At first glance, it seems like acquiring the url and headline in this situation is going to be awkward, but HTML::TokeParser makes light work of the page. The two important methods we are given by HTML::TokeParser are get_tag and get_trimmed_text.
get_tag skips forward in the HTML from our current position to the tag specified, and get_trimmed_text will grab plaintext from the current position to the end position specified. And so we can now translate our description of the BBC’s layout into methods upon our HTML::TokeParser object, $stream.
# First indication of a headline - A <div> tag is present.
while ( $tag = $stream->get_tag("div") ) {
# Inside this loop, $tag is at a <div> tag.
# But do we have a "class="bodytext">" token, too?
if ($tag->[1]{class} and $tag->[1]{class} eq 'bodytext') {
# We do!
# The next step is an <a></a> set, which we aren't interested in.
# Let's go past it to the next <a>.
$tag = $stream->get_tag('a'); $tag = $stream->get_tag('a');
# Now, we're at the <a> with the headline in.
# We need to put the contents of the 'href' token in $url.
$url = $tag->[1]{href} || "--";
# That's $url done. We can move on to $headline, and <b>
$tag = $stream->get_tag('b');
# Now we can grab $headline, by using get_trimmed_text
# up to the close of the <b> tag.
# We want <b class="h1"> or <b class="h2">.
# A regular expression will come in useful here.
$headline = $stream->get_trimmed_text('/b') \
if ($tag->[1]{class} =~ /^h[12]$/);
We’re getting there. We have the page downloaded, and we’re inside a while loop that’s going to grab every set of url and headline pairs on the page. All that’s left to do is add $url and $headline to our RSS channel; but first, some tidying up..
# We need to escape ampersands, as they start entity references in XML.
$url =~ s/&/&/g;
# The <a> tags contain relative URLs - we need to qualify these.
$url = 'http://news.bbc.co.uk'.$url;
# And that's it. We can add our pair to the RSS channel.
$rss->add_item( title => $headline, link => $url);
}
}
By the end of each iteration through the <div> tags, our $rss object is going to contain every title and link from the page. Now all we need to do is save it somewhere, and that’s done with the $rss->save method.
$rss->save("bbcnews.rss");
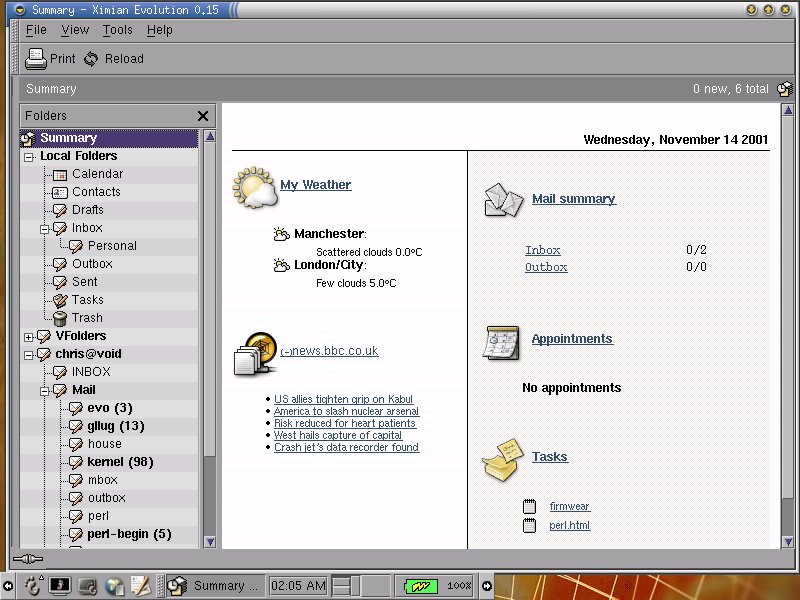
After executing our script, we get a ‘bbcnews.rss’ file dumped in the current directory, and this can be processed by any RSS parser - for example, here’s my current mail client, Evolution, adding our data to the ‘Executive Summary’ feature.
If we make this accessible on the web, as all good RSS feeds are, we can even get at this from our Slashboxes or use.perl news boxes. If you do want to make it web accessible, however, it’s probably better to periodically create the RSS file from a cron job or similar, rather than using CGI, especially if you think the RSS is going to be accessed more often than the target site will be updated.
Of course, if you’re creating an RSS feed for your own site, you have much greater control over the way you get your data. For instance, if you’re using XML to produce your web site, you can use XML transformation techniques to produce RSS - but that’s another tutorial for another time. For now, have fun, and happy spidering!
Tags
Feedback
Something wrong with this article? Help us out by opening an issue or pull request on GitHub


{kind=link}