

Why Not Translate Perl to C?
People often have the idea that automatically translating Perl to C and then compiling the C will make their Perl programs run faster, because “C is much faster than Perl.” This article explains why this strategy is unlikely to work.
Short Summary
Your Perl program is being run by the Perl interpreter. You want a C program that does the same thing that your Perl program does. A C program to do what your Perl program does would have to do most of the same things that the Perl interpreter does when it runs your Perl program. There is no reason to think that the C program could do those things faster than the Perl interpreter does them, because the Perl interpreter itself is written in very fast C.
Some detailed case studies follow.
Built-In Functions
Suppose your program needs to split a line into fields, and uses the Perl split function to do so. You want to compile this to C so it will be faster.
This is obviously not going to work, because the split function is already implemented in C. If you have the Perl source code, you can see the implementation of split in the file pp.c; it is in the function named pp_split. When your Perl program uses split, Perl calls this pp_split function to do the splitting. pp_split is written in C, and it has already been compiled to native machine code.
Now, suppose you want to translate your Perl program to C. How will you translate your split call? The only thing you can do is translate it to a call to the C pp_split function, or some other equivalent function that splits. There is no reason to believe that any C implementation of split will be faster than the pp_split that Perl already has. Years of work have gone into making pp_split as fast as possible.
You can make the same argument for all of Perl’s other built-in functions, such as join, printf, rand and readdir.
So much for built-in functions.
Data Structures
Why is Perl slow to begin with? One major reason is that its data structures are extremely flexible, and this flexibility imposes a speed penalty.
Let’s look in detail at an important example: strings. Consider this Perl code:
$x = 'foo';
$y = 'bar';
$x .= $y;
That is, we want to append $y to the end of $x. In C, this is extremely tricky. In C, you would start by doing something like this:
char *x = "foo";
char *y = "bar";
Now you have a problem. You would like to insert bar at the end of the buffer pointed to by x. But you can’t, because there is not enough room; x only points to enough space for four characters, and you need space for seven. (C strings always have an extra nul character on the end.) To append y to x, you must allocate a new buffer, and then arrange for x to point to the new buffer:
char *tmp = malloc(strlen(x) + strlen(y) + 1);
strcpy(tmp, x);
strcat(tmp, y);
x = tmp;
This works fine if x is the only pointer to that particular buffer. But if some other part of the program also had a pointer to the buffer, this code does not work. Why not? Here’s the picture of what we did:
BEFORE:
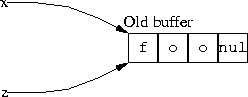
Here x and z are two variables that both contain pointers to the same buffer. We want to append bar to the end of the string. But the C code we used above doesn’t quite work, because we allocated a new region of memory to hold the result, and then pointed x to it:
AFTER x = tmp:
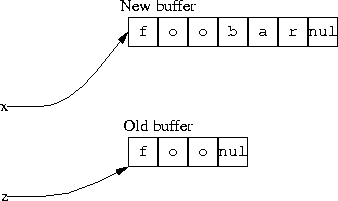
It’s tempting to think that we should just point z to the new buffer also, but in practice this is impossible. The function that is doing the appending cannot know whether there is such a z, or where it may be. There might be 100 variables like z all pointing to the old buffer, and there is no good way to keep track of them so that they can all be changed when the array moves.
Perl does support a transparent string append operation. Let’s see how this works. In Perl, a variable like $x does not point directly at the buffer. Instead, it points at a structure called an SV. (‘Scalar Value’) The SV has the pointer to the buffer, and also some other things that I do not show:
BEFORE $x .= $y
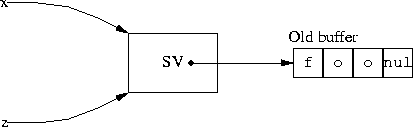
When you ask Perl to append bar to $x, it follows the pointers and finds that there is not enough space in the buffer. So, just as in C, it allocates a new buffer and stores the result in the new buffer. Then it fixes the pointer in the SV to point to the new buffer, and it throws away the old buffer:
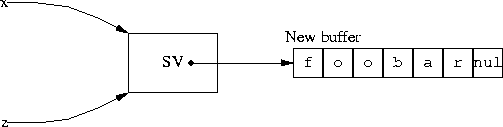
Now $x and $z have both changed. If there were any other variables sharing the SV, their values would have changed also. This technique is called “double indirection,’” and it is how Perl can support operations like .=. A similar principle applies for arrays; this is how Perl can support the push function.
The flexibility comes at a price: Whenever you want to use the value of $x, Perl must follow two pointers to get the value: The first to find the SV structure, and the second to get to the buffer with the character data. This means that using a string in Perl takes at least twice as long as in C. In C, you follow just one pointer.
If you want to compile Perl to C, you have a big problem. You would like to support operations like .= and push, but C does not support these very well. There are only three solutions:
-
Don’t support
.=This is a bad solution, because after you disallow all the Perl operations like
.=andpushwhat you have left is not very much like Perl; it is much more like C, and then you might as well just write the program in C in the first place. -
Do something extremely clever
Cleverness is in short supply this month.
:) -
Use a double-indirection technique in the compiled C code
This works, but the resulting C code will be slow, because you will have to traverse twice as many pointers each time you want to look up the value of a variable. But that is why Perl is slow! Perl is already doing the double-indirection lookup in C, and the code to do this has already been compiled to native machine code.
So again, it’s not clear that you are going to get any benefit from translating Perl to C. The slowness of Perl comes from the flexibility of the data structures. The code to manipulate these structures is already written in C. If you translate a Perl program to C, you have the choice of throwing away the flexibility of the data structure, in which case you are now writing C programs with C structures, or keeping the flexibility with the same speed penalty. You probably cannot speed up the data structures, because if anyone knew how to make the structures faster and still keep them flexible, they would already have made those changes in the C code for Perl itself.
Possible Future Work
It should now be clear that although it might not be hard to translate Perl to C, programs probably will not be faster as a result.
However, it’s possible that a sufficiently clever person could make a Perl-to-C translator that produced faster C code. The programmer would need to give hints to the translator to say how the variables were being used. For example, suppose you have an array @a. With such an array, Perl is ready for anything. You might do $a[1000000] = 'hello'; or $a[500] .= 'foo'; or $a[500] /= 17;. This flexibility is expensive. But suppose you know that this array will only hold integers and there will never be more than 1,000 integers. You might tell the translator that, and then instead of producing C code to manage a slow Perl array, the translator can produce
int a[1000];
and use a fast C array of machine integers.
To do this, you have to be very clever and you have to think of a way of explaining to the translator that @a will never be bigger than 1,000 elements and will only contain integers, or a way for the translator to guess that just from looking at the Perl program.
People are planning these features for Perl 6 right now. For example, Larry Wall, the author of Perl, plans that you will be able to declare a Perl array as
my int @a is dim(1000);
Then a Perl-to-C translator (or Perl itself) might be able to use a fast C array of machine integers rather than a slow Perl array of SVs. If you are interested, you may want to join the perl6-internals mailing list.
Tags
Feedback
Something wrong with this article? Help us out by opening an issue or pull request on GitHub

