

A Short Guide to DBI
Short guide to DBI (The Perl Database Interface Module)
General information about relational databases
Relational databases started to get to be a big deal in the 1970’s, andthey’re still a big deal today, which is a little peculiar, because they’re a 1960’s technology.
A relational database is a bunch of rectangular tables. Each row of a table is a record about one person or thing; the record contains several pieces of information called fields. Here is an example table:
LASTNAME FIRSTNAME ID POSTAL_CODE AGE SEX
Gauss Karl 119 19107 30 M
Smith Mark 3 T2V 3V4 53 M
Noether Emmy 118 19107 31 F
Smith Jeff 28 K2G 5J9 19 M
Hamilton William 247 10139 2 M
The names of the fields are LASTNAME, FIRSTNAME, ID, POSTAL_CODE, AGE, and SEX. Each line in the table is a record, or sometimes a row or tuple. For example, the first row of the table represents a 30-year-old male whose name is Karl Gauss, who lives at postal code 19107, and whose ID number is 119.
Sometimes this is a very silly way to store information. When the information naturally has a tabular structure it’s fine. When it doesn’t, you have to squeeze it into a table, and some of the techniques for doing that are more successful than others. Nevertheless, tables are simple and are easy to understand, and most of the high-performance database systems you can buy today operate under this 1960’s model.
About SQL
SQL stands for Structured Query Language. It was invented at IBM in the 1970’s. It’s a language for describing searches and modifications to a relational database.
SQL was a huge success, probably because it’s incredibly simple and anyone can pick it up in ten minutes. As a result, all the important database systems support it in some fashion or another. This includes the big players, like Oracle and Sybase, high-quality free or inexpensive database systems like MySQL, and funny hacks like Perl’s DBD::CSV module, which we’ll see later.
There are four important things one can do with a table:
SELECT
Find all the records that have a certain property
INSERT
Add new records
DELETE
Remove old records
UPDATE
Modify records that are already there
Those are the four most important SQL commands, also called queries. Suppose that the example table above is named people. Here are examples of each of the four important kinds of queries:
SELECT firstname FROM people WHERE lastname = 'Smith'
(Locate the first names of all the Smiths.)
DELETE FROM people WHERE id = 3
(Delete Mark Smith from the table)
UPDATE people SET age = age+1 WHERE id = 247
(William Hamilton just had a birthday.)
INSERT INTO people VALUES ('Euler', 'Leonhard', 248, NULL, 58, 'M')
(Add Leonhard Euler to the table.)
There are a bunch of other SQL commands for creating and discarding tables, for granting and revoking access permissions, for committing and abandoning transactions, and so forth. But these four are the important ones. Congratulations; you are now a SQL programmer. For the details, go to any reasonable bookstore and pick up a SQL quick reference.
Every database system is a little different. You talk to some databases over the network and make requests of the database engine; other databases you talk to through files or something else.
Typically when you buy a commercial database, you get a library with it. The vendor has written some functions for talking to the database in some language like C, compiled the functions, and the compiled code is the library. You can write a C program that calls the functions in the library when it wants to talk to the database.
Every vendor’s library is different. The names of the functions vary, and the order in which you call them varies, and the details of passing queries to the functions and getting the data back out will vary. Some libraries, like Oracle’s, are very thin—they just send the query over to the network to the real database and let the giant expensive real database engine deal with it directly. Other libraries will do more predigestion of the query, and more work afterwards to turn the data into a data structure. Some databases will want you to spin around three times and bark like a chicken; others want you to stand on your head and drink out of your sneaker.
What DBI is For
There’s a saying that any software problem can be solved by adding a layer of indirection. That’s what Perl’s DBI (`Database Interface’) module is all about. It was written by Tim Bunce.
DBI is designed to protect you from the details of the vendor libraries. It has a very simple interface for saying what SQL queries you want to make, and for getting the results back. DBI doesn’t know how to talk to any particular database, but it does know how to locate and load in DBD (`Database Driver’) modules. The DBD modules have the vendor libraries in them and know how to talk to the real databases; there is one DBD module for every different database.
When you ask DBI to make a query for you, it sends the query to the appropriate DBD module, which spins around three times or drinks out of its sneaker or whatever is necessary to communicate with the real database. When it gets the results back, it passes them to DBI. Then DBI gives you the results. Since your program only has to deal with DBI, and not with the real database, you don’t have to worry about barking like a chicken.
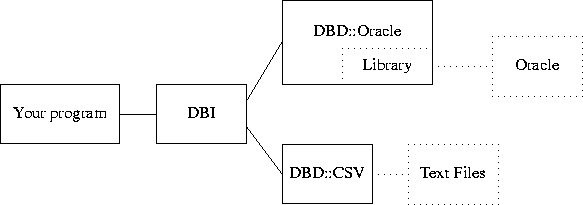
Here’s your program talking to the DBI library. You are using two databases at once. One is an Oracle database server on some other machine, and another is a DBD::CSV database that stores the data in a bunch of plain text files on the local disk.
Your program sends a query to DBI, which forwards it to the appropriate DBD module; let’s say it’s DBD::Oracle. DBD::Oracle knows how to translate what it gets from DBI into the format demanded by the Oracle library, which is built into it. The library forwards the request across the network, gets the results back, and returns them to DBD::Oracle. DBD::Oracle returns the results to DBI as a Perl data structure. Finally, your program can get the results from DBI.
On the other hand, suppose that your program was querying the text files. It would prepare the same sort of query in exactly the same way, and send it to DBI in exactly the same way. DBI would see that you were trying to talk to the DBD::CSV database and forward the request to the DBD::CSV module. The DBD::CSV module has Perl functions in it that tell it how to parse SQL and how to hunt around in the text files to find the information you asked for. It then returns the results to DBI as a Perl data structure. Finally, your program gets the results from DBI in exactly the same way that it would have if you were talking to Oracle instead.
There are two big wins that result from this organization. First, you don’t have to worry about the details of hunting around in text files or talking on the network to the Oracle server or dealing with Oracle’s library. You just have to know how to talk to DBI.
Second, if you build your program to use Oracle, and then the following week upper management signs a new Strategic Partnership with Sybase, it’s easy to convert your code to use Sybase instead of Oracle. You change exactly one line in your program, the line that tells DBI to talk to DBD::Oracle, and have it use DBD::Sybase instead. Or you might build your program to talk to a cheap, crappy database like MS Access, and then next year when the application is doing well and getting more use than you expected, you can upgrade to a better database next year without changing any of your code.
There are DBD modules for talking to every important kind of SQL database. DBD::Oracle will talk to Oracle, and DBD::Sybase will talk to Sybase. DBD::ODBC will talk to any ODBC database including Microsoft Acesss. (ODBC is a Microsoft invention that is analogous to DBI itself. There is no DBD module for talking to Access directly.) DBD::CSV allows SQL queries on plain text files. DBD::mysql talks to the excellent MySQL database from TCX DataKonsultAB in Sweden. (MySQL is a tremendous bargain: It’s $200 for commercial use, and free for noncommerical use.)
Example of How to Use DBI
Here’s a typical program. When you run it, it waits for you to type a last name. Then it searches the database for people with that last name and prints out the full name and ID number for each person it finds. For example:
Enter name> Noether
118: Emmy Noether
Enter name> Smith
3: Mark Smith
28: Jeff Smith
Enter name> Snonkopus
No names matched `Snonkopus'.
Enter name> ^D
Here is the code:
use DBI;
my $dbh = DBI->connect('DBI:Oracle:payroll')
or die "Couldn't connect to database: " . DBI->errstr;
my $sth = $dbh->prepare('SELECT * FROM people WHERE lastname = ?')
or die "Couldn't prepare statement: " . $dbh->errstr;
print "Enter name> ";
while ($lastname = <>) { # Read input from the user
my @data;
chomp $lastname;
$sth->execute($lastname) # Execute the query
or die "Couldn't execute statement: " . $sth->errstr;
# Read the matching records and print them out
while (@data = $sth->fetchrow_array()) {
my $firstname = $data[1];
my $id = $data[2];
print "\t$id: $firstname $lastname\n";
}
if ($sth->rows == 0) {
print "No names matched `$lastname'.\n\n";
}
$sth->finish;
print "\n";
print "Enter name> ";
}
$dbh->disconnect;
use DBI;
This loads in the DBI module. Notice that we don’t have to load in any DBD module. DBI will do that for us when it needs to.
my $dbh = DBI->connect('DBI:Oracle:payroll');
or die "Couldn't connect to database: " . DBI->errstr;
The connect call tries to connect to a database. The first argument, DBI:Oracle:payroll, tells DBI what kind of database it is connecting to. The Oracle part tells it to load DBD::Oracle and to use that to communicate with the database. If we had to switch to Sybase next week, this is the one line of the program that we would change. We would have to change Oracle to Sybase.
payroll is the name of the database we will be searching. If we were going to supply a username and password to the database, we would do it in the connect call:
my $dbh = DBI->connect('DBI:Oracle:payroll', 'username', 'password')
or die "Couldn't connect to database: " . DBI->errstr;
If DBI connects to the database, it returns a database handle object, which we store into $dbh. This object represents the database connection. We can be connected to many databases at once and have many such database connection objects.
If DBI can’t connect, it returns an undefined value. In this case, we use die to abort the program with an error message. DBI->errstr returns the reason why we couldn’t connect—``Bad password’’ for example.
my $sth = $dbh->prepare('SELECT * FROM people WHERE lastname = ?')
or die "Couldn't prepare statement: " . $dbh->errstr;
The prepare call prepares a query to be executed by the database. The argument is any SQL at all. On high-end databases, prepare will send the SQL to the database server, which will compile it. If prepare is successful, it returns a statement handle object which represents the statement; otherwise it returns an undefined value and we abort the program. $dbh->errstr will return the reason for failure, which might be ``Syntax error in SQL’’. It gets this reason from the actual database, if possible.
The ? in the SQL will be filled in later. Most databases can handle this. For some databases that don’t understand the ?, the DBD module will emulate it for you and will pretend that the database understands how to fill values in later, even though it doesn’t.
print "Enter name> ";
Here we just print a prompt for the user.
while ($lastname = <>) { # Read input from the user
...
}
This loop will repeat over and over again as long as the user enters a last name. If they type a blank line, it will exit. The Perl <> symbol means to read from the terminal or from files named on the command line if there were any.
my @data;
This declares a variable to hold the data that we will get back from the database.
chomp $lastname;
This trims the newline character off the end of the user’s input.
$sth->execute($lastname) # Execute the query
or die "Couldn't execute statement: " . $sth->errstr;
execute executes the statement that we prepared before. The argument $lastname is substituted into the SQL in place of the ? that we saw earlier. execute returns a true value if it succeeds and a false value otherwise, so we abort if for some reason the execution fails.
while (@data = $sth->fetchrow_array()) {
...
}
fetchrow_array returns one of the selected rows from the database. You get back an array whose elements contain the data from the selected row. In this case, the array you get back has six elements. The first element is the person’s last name; the second element is the first name; the third element is the ID, and then the other elements are the postal code, age, and sex.
Each time we call fetchrow_array, we get back a different record from the database. When there are no more matching records, fetchrow_array returns the empty list and the while loop exits.
my $firstname = $data[1];
my $id = $data[2];
These lines extract the first name and the ID number from the record data.
print "\t$id: $firstname $lastname\n";
This prints out the result.
if ($sth->rows == 0) {
print "No names matched `$lastname'.\n\n";
}
The rows method returns the number of rows of the database that were selected. If no rows were selected, then there is nobody in the database with the last name that the user is looking for. In that case, we print out a message. We have to do this after the while loop that fetches whatever rows were available, because with some databases you don’t know how many rows there were until after you’ve gotten them all.
$sth->finish;
print "\n";
print "Enter name> ";
Once we’re done reporting about the result of the query, we print another prompt so that the user can enter another name. finish tells the database that we have finished retrieving all the data for this query and allows it to reinitialize the handle so that we can execute it again for the next query.
$dbh->disconnect;
When the user has finished querying the database, they type a blank line and the main while loop exits. disconnect closes the connection to the database.
Cached Queries
Here’s a function which looks up someone in the example table, given their ID number, and returns their age:
sub age_by_id {
# Arguments: database handle, person ID number
my ($dbh, $id) = @_;
my $sth = $dbh->prepare('SELECT age FROM people WHERE id = ?')
or die "Couldn't prepare statement: " . $dbh->errstr;
$sth->execute($id)
or die "Couldn't execute statement: " . $sth->errstr;
my ($age) = $sth->fetchrow_array();
return $age;
}
It prepares the query, executes it, and retrieves the result.
There’s a problem here though. Even though the function works correctly, it’s inefficient. Every time it’s called, it prepares a new query. Typically, preparing a query is a relatively expensive operation. For example, the database engine may parse and understand the SQL and translate it into an internal format. Since the query is the same every time, it’s wasteful to throw away this work when the function returns.
Here’s one solution:
{ my $sth;
sub age_by_id {
# Arguments: database handle, person ID number
my ($dbh, $id) = @_;
if (! defined $sth) {
$sth = $dbh->prepare('SELECT age FROM people WHERE id = ?')
or die "Couldn't prepare statement: " . $dbh->errstr;
}
$sth->execute($id)
or die "Couldn't execute statement: " . $sth->errstr;
my ($age) = $sth->fetchrow_array();
return $age;
}
}
There are two big changes to this function from the previous version. First, the $sth variable has moved outside of the function; this tells Perl that its value should persist even after the function returns. Next time the function is called, $sth will have the same value as before.
Second, the prepare code is in a conditional block. It’s only executed if $sth does not yet have a value. The first time the function is called, the prepare code is executed and the statement handle is stored into $sth. This value persists after the function returns, and the next time the function is called, $sth still contains the statement handle and the prepare code is skipped.
Here’s another solution:
sub age_by_id {
# Arguments: database handle, person ID number
my ($dbh, $id) = @_;
my $sth = $dbh->prepare_cached('SELECT age FROM people WHERE id = ?')
or die "Couldn't prepare statement: " . $dbh->errstr;
$sth->execute($id)
or die "Couldn't execute statement: " . $sth->errstr;
my ($age) = $sth->fetchrow_array();
return $age;
}
Here the only change to to replace prepare with prepare_cached. The prepare_cached call is just like prepare, except that it looks to see if the query is the same as last time. If so, it gives you the statement handle that it gave you before.
Transactions
Many databases support transactions. This means that you can make a whole bunch of queries which would modify the databases, but none of the changes are actually made. Then at the end you issue the special SQL query COMMIT, and all the changes are made simultaneously. Alternatively, you can issue the query ROLLBACK, in which case all the queries are thrown away.
As an example of this, consider a function to add a new employee to a database. The database has a table called employees that looks like this:
FIRSTNAME LASTNAME DEPARTMENT_ID
Gauss Karl 17
Smith Mark 19
Noether Emmy 17
Smith Jeff 666
Hamilton William 17
and a table called departments that looks like this:
ID NAME NUM_MEMBERS
17 Mathematics 3
666 Legal 1
19 Grounds Crew 1
The mathematics department is department #17 and has three members: Karl Gauss, Emmy Noether, and William Hamilton.
Here’s our first cut at a function to insert a new employee. It will return true or false depending on whether or not it was successful:
sub new_employee {
# Arguments: database handle; first and last names of new employee;
# department ID number for new employee's work assignment
my ($dbh, $first, $last, $department) = @_;
my ($insert_handle, $update_handle);
my $insert_handle =
$dbh->prepare_cached('INSERT INTO employees VALUES (?,?,?)');
my $update_handle =
$dbh->prepare_cached('UPDATE departments
SET num_members = num_members + 1
WHERE id = ?');
die "Couldn't prepare queries; aborting"
unless defined $insert_handle && defined $update_handle;
$insert_handle->execute($first, $last, $department) or return 0;
$update_handle->execute($department) or return 0;
return 1; # Success
}
We create two handles, one for an insert query that will insert the new employee’s name and department number into the employees table, and an update query that will increment the number of members in the new employee’s department in the department table. Then we execute the two queries with the appropriate arguments.
There’s a big problem here: Suppose, for some reason, the second query fails. Our function returns a failure code, but it’s too late, it has already added the employee to the employees table, and that means that the count in the departments table is wrong. The database now has corrupted data in it.
The solution is to make both updates part of the same transaction. Most databases will do this automatically, but without an explicit instruction about whether or not to commit the changes, some databases will commit the changes when we disconnect from the database, and others will roll them back. We should specify the behavior explicitly.
Typically, no changes will actually be made to the database until we issue a commit. The version of our program with commit looks like this:
sub new_employee {
# Arguments: database handle; first and last names of new employee;
# department ID number for new employee's work assignment
my ($dbh, $first, $last, $department) = @_;
my ($insert_handle, $update_handle);
my $insert_handle =
$dbh->prepare_cached('INSERT INTO employees VALUES (?,?,?)');
my $update_handle =
$dbh->prepare_cached('UPDATE departments
SET num_members = num_members + 1
WHERE id = ?');
die "Couldn't prepare queries; aborting"
unless defined $insert_handle && defined $update_handle;
my $success = 1;
$success &&= $insert_handle->execute($first, $last, $department);
$success &&= $update_handle->execute($department);
my $result = ($success ? $dbh->commit : $dbh->rollback);
unless ($result) {
die "Couldn't finish transaction: " . $dbh->errstr
}
return $success;
}
We perform both queries, and record in $success whether they both succeeded. $success will be true if both queries succeeded, false otherwise. If the queries succeded, we commit the transaction; otherwise, we roll it back, cancelling all our changes.
The problem of concurrent database access is also solved by transactions. Suppose that queries were executed immediately, and that some other program came along and examined the database after our insert but before our update. It would see inconsistent data in the database, even if our update would eventually have succeeded. But with transactions, all the changes happen simultaneously when we do the commit, and the changes are committed automatically, which means that any other program looking at the database either sees all of them or none.
do
If you’re doing an UPDATE, INSERT, or DELETE there is no data that comes back from the database, so there is a short cut. You can say
$dbh->do('DELETE FROM people WHERE age > 65');
for example, and DBI will prepare the statement, execute it, and finish it. do returns a true value if it succeeded, and a false value if it failed. Actually, if it succeeds it returns the number of affected rows. In the example it would return the number of rows that were actually deleted. (DBI plays a magic trick so that the value it turns is true even when it is 0. This is bizarre, because 0 is usually false in Perl. But it’s convenient because you can use it either as a number or as a true-or-false success code, and it works both ways.)
AutoCommit
If your transactions are simple, you can save yourself the trouble of having to issue a lot of commits. When you make the connect call, you can specify an AutoCommit option which will perform an automatic commit operation after every successful query. Here’s what it looks like:
my $dbh = DBI->connect('DBI:Oracle:payroll',
{AutoCommit => 1},
)
or die "Couldn't connect to database: " . DBI->errstr;
Automatic Error Handling
When you make the connect call, you can specify a RaiseErrors option that handles errors for you automatically. When an error occurs, DBI will abort your program instead of returning a failure code. If all you want is to abort the program on an error, this can be convenient:
my $dbh = DBI->connect('DBI:Oracle:payroll',
{RaiseError => 1},
)
or die "Couldn't connect to database: " . DBI->errstr;
Don’t do This
People are always writing code like this:
while ($lastname = <>) {
my $sth = $dbh->prepare("SELECT * FROM people
WHERE lastname = '$lastname'");
$sth->execute();
# and so on ...
}
Here we interpolated the value of $lastname directly into the SQL in the prepare call.
This is a bad thing to do for three reasons.
First, prepare calls can take a long time. The database server has to compile the SQL and figure out how it is going to run the query. If you have many similar queries, that is a waste of time.
Second, it will not work if $lastname contains a name like O’Malley or D’Amico or some other name with an '. The ' has a special meaning in SQL, and the database will not understand when you ask it to prepare a statement that looks like
SELECT * FROM people WHERE lastname = 'O'Malley'
It will see that you have three 's and complain that you don’t have a fourth matching ' somewhere else.
Finally, if you’re going to be constructing your query based on a user input, as we did in the example program, it’s unsafe to simply interpolate the input directly into the query, because the user can construct a strange input in an attempt to trick your program into doing something it didn’t expect. For example, suppose the user enters the following bizarre value for $input:
x' or lastname = lastname or lastname = 'y
Now our query has become something very surprising:
SELECT * FROM people WHERE lastname = 'x'
or lastname = lastname or lastname = 'y'
The part of this query that our sneaky user is interested in is the second or clause. This clause selects all the records for which lastname is equal to lastname; that is, all of them. We thought that the user was only going to be able to see a few records at a time, and now they’ve found a way to get them all at once. This probably wasn’t what we wanted.
| References |
• A complete list of DBD modules are available here |
People go to all sorts of trouble to get around these problems with interpolation. They write a function that puts the last name in quotes and then backslashes any apostrophes that appear in it. Then it breaks because they forgot to backslash backslashes. Then they make their escape function better. Then their code is a big message because they are calling the backslashing function every other line. They put a lot of work into it the backslashing function, and it was all for nothing, because the whole problem is solved by just putting a ? into the query, like this
SELECT * FROM people WHERE lastname = ?
All my examples look like this. It is safer and more convenient and more efficient to do it this way.
Tags
Feedback
Something wrong with this article? Help us out by opening an issue or pull request on GitHub

